
DeepMind algorithm remembers how to beat you at Space Invaders
In 2014 when DeepMind burst into prominent view, it taught its machine learning systems how to play Atari games. The system could learn to defeat the games, and score higher than humans, but not remember how it had done so.
For each of the Atari games, a separate neural network had to be created. The same system could not be used to play Space Invaders and Breakout without the information for both being given to the artificial intelligence at the same time. Now, a team of DeepMind and Imperial College London researchers have created an algorithm that allows its neural networks to learn, retain the information, and use it again.
“Previously, we had a system that could learn to play any game, but it could only learn to play one game,” James Kirkpatrick, a research scientist at DeepMind and the lead author of its new research paper, tells WIRED. “Here we are demonstrating a system that can learn to play several games one after the other”.
The work, published in the Proceedings of the National Academy of Sciences journal, explains how DeepMind’s AI can learn in sequences using supervised learning and reinforcement learning tests. This is also explained in a blog post from the company.
“The ability to learn tasks in succession without forgetting is a core component of biological and artificial intelligence,” the computer scientists write in the paper. Kirkpatrick says a “significant shortcoming” in neural networks and artificial intelligence has been its inability to transfer what it has learned from one task to the next.
The group says it has been able to show “continual learning” that’s based on ‘synaptic consolidation’. In the human brain, the process is described as “the basis of learning and memory”.
To give the AI systems a memory, the DeepMind researchers developed an algorithm called ‘elastic weight consolidation’ (EWC). “Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks,” the paper says. Kirkpatrick explains that the algorithm selects what it learned to successfully play one game and keeps the most useful parts.
“We only allow them to change very slowly [between games],” he says. “That way there is room to learn the new task but the changes we’ve applied do not override what we’ve learned before”.
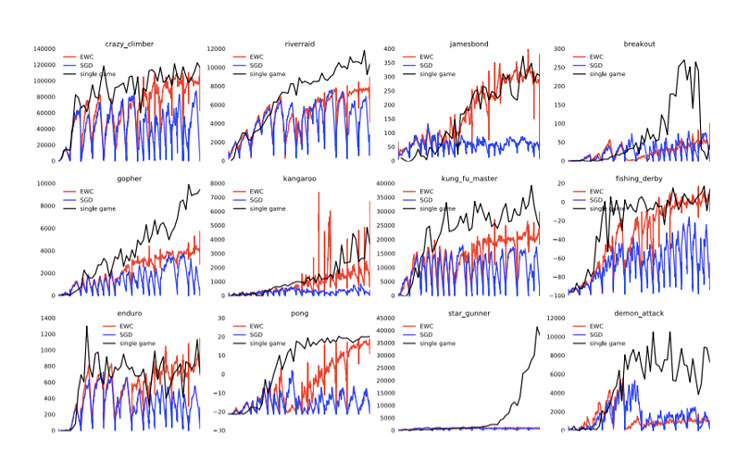
To test the algorithm, DeepMind used the deep neural networks, called Deep Q-Network (DQN), it had previously used to conquer the Atari games. However, this time the DQN was “enhanced” with the EWC algorithm. It tested the algorithm and the neural network on a random selection of ten Atari games, which the AI had already proven could to be as good at as a human player. Each game was played 20 million times before the system automatically moved to the next Atari game.
“Previously, DQN had to learn how to play each game individually,” the paper says. “Whereas augmenting the DQN agent with EWC allows it to learn many games in sequence without suffering from catastrophic forgetting.”
Essentially, the deep neural network using the EWC algorithm was able to learn to play one game and then transfer what it had learnt to play a brand new game.
However, the system is by no means perfect. While it is able to learn from its previous experiences and retain the most useful information, it isn’t able to perform as well as a neural network that completes just one game.
“At the moment, we have demonstrated sequential learning but we haven’t proved it is an improvement on the efficiency of learning,” Kirkpatrick says. “Our next steps are going to try and leverage sequential learning to try and improve on real-world learning.”
Comments are closed, but trackbacks and pingbacks are open.